Sync your Letterboxd film data with Google Sheets & Eleventy
Posted on: 1 March 2023
I like watching films, and I like keeping track of what I watch. I’ve done this for some years via Letterboxd, a decent little app for accomplishing this task, including reviewing what you watch and keeping a to-watch list.
I wanted to integrate with Letterboxd on my website so I could “own” my reviews in case the service went kaput. That lead me to 2 options: integrate with their API, or consume the personalised XML feed URL they provide.
Unfortunately, their API is invite-only and hasn’t seen a lot of movement. After Googling around, I quickly discounted this as a viable option. The second is simple and useful enough - a basic XML feed of your last 50 reviews - but it is limited, with no option for viewing beyond your last 50.
Letterboxd does apparently offer a third option of exporting your data to CSV. But this is a manual operation to keep synced and one I wanted to avoid.
My solution
Instead of consuming the RSS feed directly, limiting me to my last 50 reviews, here's what I ended up doing:
- Before building my static site, run a sync-letterboxd.js script
- This script requests and parses the latest XML file of my recently watched movies
- It stores new entries in a Google Sheet (new = not found in the sheet)
- Eleventy parses the Google Sheet to display all my watched films
Why Google Sheets?
A spreadsheet is typically a poor way to store data you may want to query. However, as I’m using Eleventy, a static-site generator, I don’t necessarily need to query this data, I simply need to retrieve all entries and pass that data into a template to build. So, it’s actually quite efficient at that.
Add to that the benefits Google Sheets offers - easy to share, modify, export, etc.
I use the google-spreadsheet NPM package to read and write rows in an intuitive way.
The sync script
Firstly, what libraries am I importing?
const CachedSpreadsheet = require('../src/cached-spreadsheet');
const EleventyFetch = require('@11ty/eleventy-fetch');
const xml2js = require('xml2js');
const { parse } = require('node-html-parser');
const dotenv = require('dotenv');CachedSpreadsheet is a helper class I wrote for abstracting the interaction with cached data from a Google Sheet.
eleventy-fetch is an official Eleventy package that allows me to easily fetch and cache the Letterboxd URL. I cache this for a week as that’s how often I update the weekly data feed on my site.
xml2j is a utility package for easily parsing the XML Letterboxd feed into a Javascript object
node-html-parser is used for parsing the HTML snippet embedded in the XML which represents the review description.
dotenv allows me to use an .env file to store environment data such as API keys (for accessing the Google Sheets API).
The main function
async function syncLetterboxd() {
const spreadsheet = new CachedSpreadsheet('<SHEET ID>');
const importer = new FilmImporter(spreadsheet);
await importer.downloadRssFeed();
const storedFilms = Object.fromEntries((await spreadsheet.sheet()).map(film => [film.url, film]));
const newFilms = importer.reviews.reject(film => storedFilms[film.link[0]]);
if (newFilms.length) {
for (let i in newFilms) {
await importer.writeFilmData(newFilms[i]);
}
} else {
console.log('Nothing to sync. Spreadsheet is up to date.');
}
}First we grab an instance of the the cached films Google Sheet, identified by the sheet ID. The sheet ID can be extracted from the URL of your Google Sheet in the browser. CachedSpreadsheet's default caching duration is 1 hour, but there’s no rhyme or reason to this number; it was merely picked to minimise requests to the Google API during development.
Note: CachedSpreadsheet makes use of the eleventy-fetch package mentioned earlier to store the spreadsheet data in the .cache directory of the app. More on this later.
Next we initialise a custom class - FilmImporter, passing it the CachedSpreadsheet object.
We then make a call to download the RSS feed from Letterboxd, waiting for the HTTP response before continuing, await.
Next, we build a dictionary of stored films in the sheet (identified by the Letterboxd review URL). Then we loop over the films imported from the XML, and disregard those found in the Google Sheet, storing the result in a newFilms variable.
Finally, if newFilms is not empty, we loop over it, and synchronously write each film to the Google Sheet as a new row.
If there are no new films to sync, we output a message that the spreadsheet is up to date, for peace of mind.
Downloading the RSS feed
async downloadRssFeed() {
const letterboxd = await EleventyFetch('https://letterboxd.com/samdking/rss/', {
duration: "1d",
type: "text"
});
const feed = await xml2js.parseStringPromise(letterboxd);
this.reviews = feed.rss.channel[0].item;
}The eleventy-fetch package makes this simple. We make a call to my Letterboxd RSS feed URL, indicating we want to cache the response for 1 day. The duration value chosen is semi-arbitrary, but since i’m unlikely to watch more than 1 film a day, this seems a logical amount to avoid spamming the URL.
Next, we pass the response promise through the xml2js package function parseStringPromise. This returns a nice JS object which we can inspect. We dig into the exact data we want in the XML structure and store it in the field this.reviews.
Writing the film data
async writeFilmData(film) {
const { img, description } = this.deconstructDescription(film.description);
console.log(`Writing ${film.title[0]} to the spreadsheet`);
await this.cache.writeRow({
title: film.title[0],
url: film.link[0],
description,
posterImage: img.getAttribute('src'),
name: film['letterboxd:filmTitle'][0],
watched: new Date(film['letterboxd:watchedDate']).toLocaleDateString('en-GB'),
});
return new Promise(resolve => setTimeout(resolve, 800));
}
deconstructDescription(html) {
const root = parse(html);
return {
img: root.querySelector('img'),
description: root.querySelector('p:nth-child(2)').rawText,
}
}writeFilmData does 2 things: 1) deconstructs the review description from the HTML returned by Letterboxd; 2) writes the nicely formatted data to the Google Sheet.
Letterboxd returns the review description in the following format:
<p><img src="<film poster image URL>"/></p>
<p>Your text review</p>So it’s pretty intuitive to pick apart. For robustness, we use the node-html-parser library which takes an HTML string and allows you to interact with it as if it’s in the DOM. Both the image URL and the text description can be plucked out by highlighting the selectors using the querySelector method on the root node.
You may argue using a library like this may be overkill for the simplistic HTML, and you may have a point.
Now that we have the poster image URL and text description, we can construct the rest of the data and return it as an object to import into the Google Sheet. We grab the “title” (which Letterboxd formats with the release year and star review, e.g. "Stand by Me, 1986 - ★★★★"); the review URL; the raw name of the film; and the date it was watched.
This object is passed into the writeRow method, called on the CachedSpreadsheet object. We use await to ensure this process completes before writing any more data. And so we can stay within Google’s rate limits, we use a little bit of code to delay the execution of the script for 800ms.
Note that the keys in this hash must match columns in the Google Sheet you're writing to. Here's how mine looks after setting up the sheet and syncing some data:
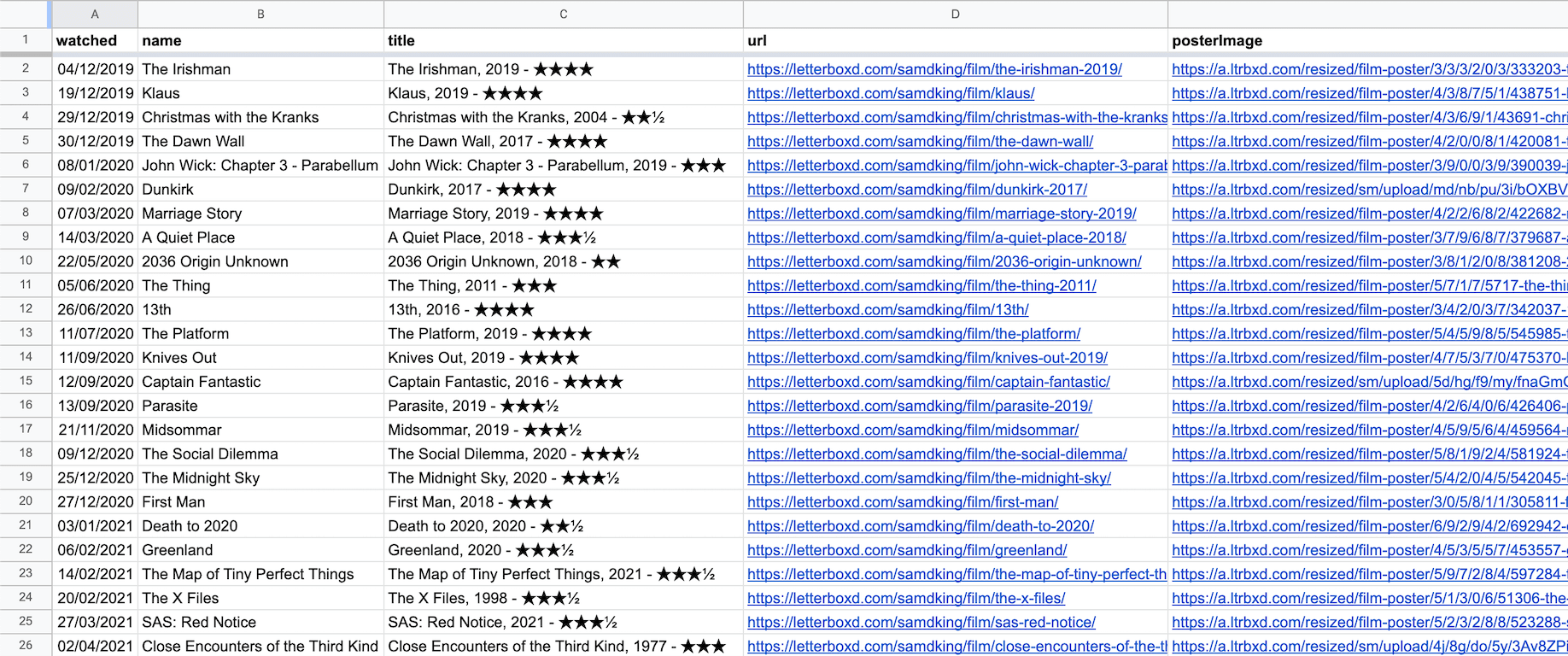
The cached Google Sheet object
The CachedSpreadsheet class does a lot of the heavy lifting of this script. It's responsible for retrieving, writing and caching the data to & from Google Sheets. From the above code, we can deduce this object responds to the following 3 methods:
sheet(returns a cached array of rows in the sheet)clearCache(clears the cache)writeRow(writes the row to the sheet, and clears the cache)
This is a follow-up article for another day (soon). Stay tuned!
Running the script
sync-letterboxd.js is a Node script run by NPM. I define how to run the script in my package.json “scripts” section:
{
scripts: {
"sync-letterboxd": "node scripts/sync-letterboxd.js"
}
}This is run as part of my build script, prior to building my Eleventy site. This is achieved by calling this sync script, sequentially, prior to my site-building command (details omitted for brevity):
{
scripts: {
"sync-letterboxd": "node scripts/sync-letterboxd.js",
"prod:eleventy": "eleventy --input=content",
"build": "npm-run-all sync-letterboxd prod:eleventy"
}
}Running sequentially ensures all my film data is up to date before I instruct Eleventy to build the the pages.
Keeping synced
This script relies on being run at least as often as it takes you to watch 50 films. This is tongue-in-cheek, but the crux of this approach is, it relies on a manual sync.
I have this sync running every time I build or serve the site in development (by running npm run sync-letterboxd. Since I build the site at least weekly, and my film-watching cadence is around one-a-week, I have absolutely no issue syncing all my watched films.
If you’re a power-watcher and don’t update your site very often, you’ll probably want to set up an automated job that rebuilds your site regularly, e.g. once a week. As long as you’re not watching more than 50 films in that duration, the script will sync all your films fine.
Conclusion
There you have it. A way to get around Letterboxd's 50 limit on your reviews. If you're not fussed about getting reviews beyond this, you can simply parse the RSS feed and build straight from that. But I love historical data, so getting as much data as I could out of Letterboxd was a priority for me.
I'm happy to offer any guidance on getting a similar system set up. Let me know on Twitter or drop me an email if you could use some help.